Inside the AI Red Teaming CTF: what 200+ players taught us about breaking and defending LLMs
A joint HackerOne & Hack The Box paper distills lessons from 217 active players across 11 challenges, showing where simple jailbreaks thrive and where layered defenses still win.



Table of Contents
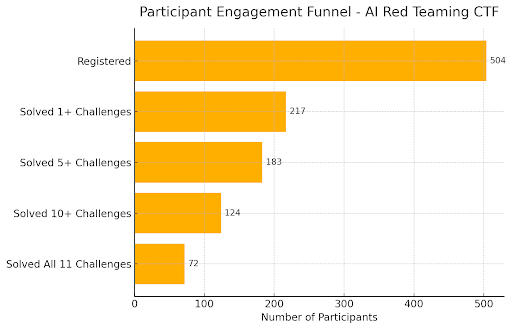
In our paper, Breaking Guardrails, Facing Walls, we analyze ai_gon3_rogu3, a 10‑day AI red teaming CTF co-run by HackerOne and Hack The Box. Among 504 registrants, 217 were active participants who attempted 11 jeopardy‑style challenges spanning output manipulation and sensitive‑data exfiltration.
The goal was to understand which adversarial strategies succeed in practice and where modern defenses still hold.
The CTF combined guardrail‑evasion, prompt‑injection, output‑manipulation, and data‑extraction scenarios mapped to the OWASP Top 10 for LLMs (e.g., LLM01 Prompt Injection, LLM02 Data Leakage, LLM04 Insecure Output Handling, LLM05 Excessive Agency, LLM06 Sensitive Information Disclosure, LLM09 Overreliance).
This framing lets us compare performance across real attack families rather than one‑off tricks.
The top findings include:
-
Simple bypasses are common; layered defenses still win. Among active players, completion drops from ~98% on the introductory task to ~34% on the final multi‑step scenario.
-
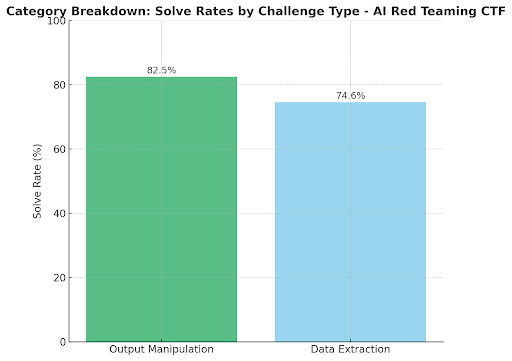
“Social‑engineering the model” is easier than exfiltrating secrets. Output‑manipulation tasks saw ≈82.5% success vs. ≈74.6% for data‑extraction challenges.
-
Format obfuscation works too well. Encoding/format tricks (e.g., JSON/base64) routinely bypass pattern‑matching filters, evidence that defenses need deeper semantic checks.
-
The talent distribution is bimodal. Roughly a third of participants solved everything, while many solved very little—underscoring a clear skills gap that training and better challenge design can help close.
What these results mean for defenders
The results confirm that many single‑turn filters are trivial to bypass, but layered, multi‑turn, and role‑aware defenses still frustrate even skilled adversaries. Investing in compound mitigations (policy + context isolation + output validation), guarding against indirect prompt injection, and testing for insecure output handling can reduce risk where today’s models are prone to manipulation.
How we measured player behavior
We analyzed platform logs for every challenge instance, solve, and attempt. In total: 504 registrants; 217 active players; 11 challenges. The introductory task reached 98.2% completion among active teams; the final scenario, 34.1%. The study includes time‑to‑first‑solve distributions and challenge‑by‑challenge ownership to separate participation timing from problem‑solving latency. (Figures 3–6, pp. 5–7.)
Read the full research
The full write‑up details solve‑rate curves, category‑wise performance, and mappings to OWASP LLM Top 10 and MITRE ATLAS, plus recommendations for CTF and product‑security teams.
Together, HackerOne and Hack The Box will continue to build community pathways, challenges, and adversarial testing programs that turn these insights into safer AI systems.
See what our AI red teaming challenge revealed in Breaking Guardrails, Facing Walls.















